Grounding Language with Visual Affordances over Unstructured Data
1University of Freiburg,
2University of Nuremberg
Recent works have shown that Large Language Models (LLMs) can be applied to ground natural language to a wide variety of robot skills. However, in practice, learning multi-task, language-conditioned robotic skills typically requires large-scale data collection and frequent human intervention to reset the environment or help correcting the current policies. In this work, we propose a novel approach to efficiently learn general-purpose language-conditioned robot skills from unstructured, offline and reset-free data in the real world by exploiting a self-supervised visuo-lingual affordance model, which requires annotating as little as 1% of the total data with language.
We evaluate our method in extensive experiments both in simulated and real-world robotic tasks, achieving state-of-the-art performance on the challenging CALVIN benchmark and learning over 25 distinct visuomotor manipulation tasks with a single policy in the real world. We find that when paired with LLMs to break down abstract natural language instructions into subgoals via few-shot prompting, our method is capable of completing long-horizon, multi-tier tasks in the real world, while requiring an order of magnitude less data than previous approaches.
HULC++ first processes a language instruction and an image from a static camera to predict the afforded region and guides the robot to its vicinity. Once inside this area, we switch to a language conditioned imitation learning agent that receives RGB observations from both a gripper and a static camera, and learns 7-DoF goal-reaching policies end-to-end. Both modules learn from the same free-form, unstructured dataset and require as little as 1% of language annotations.
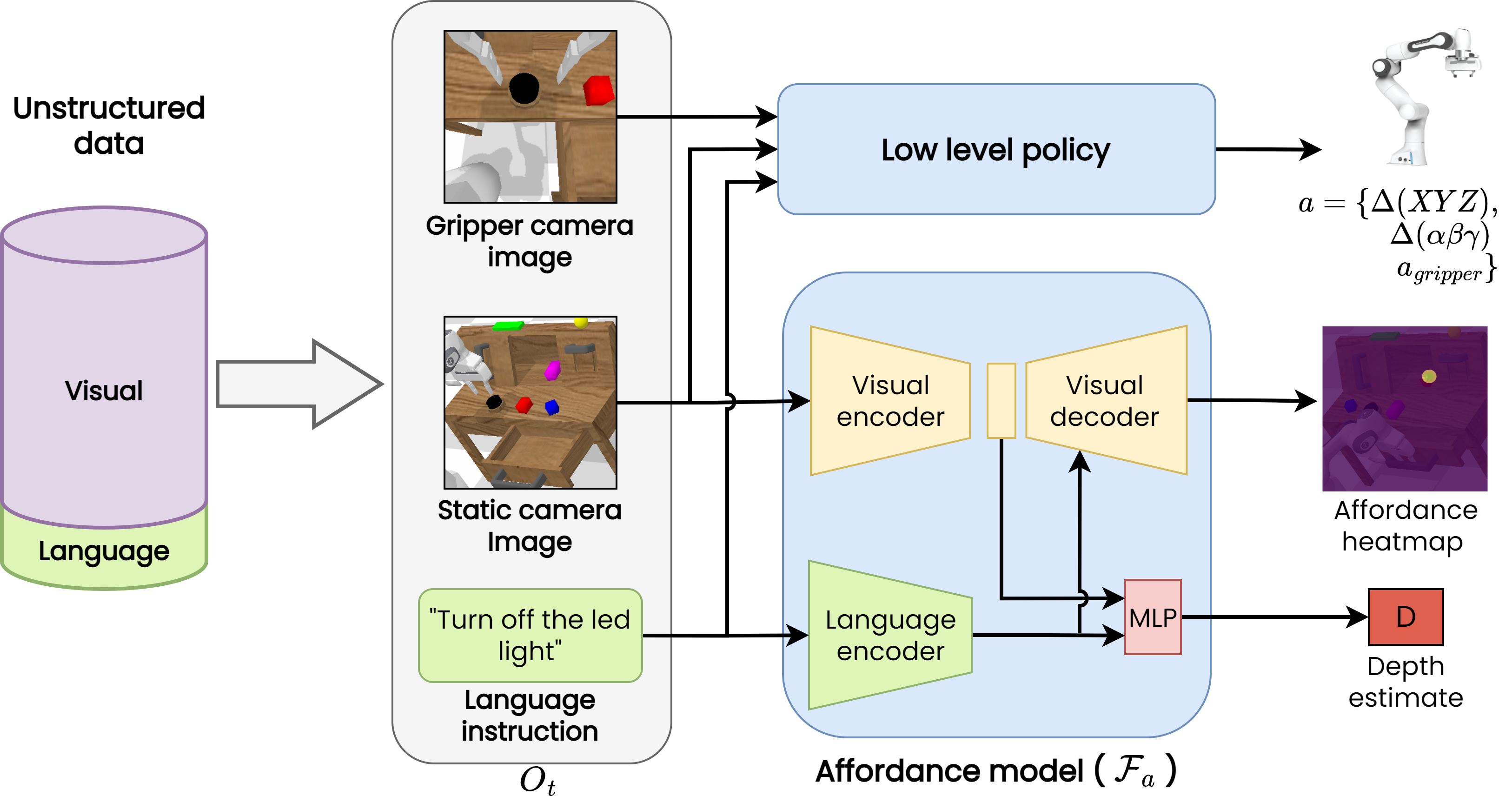
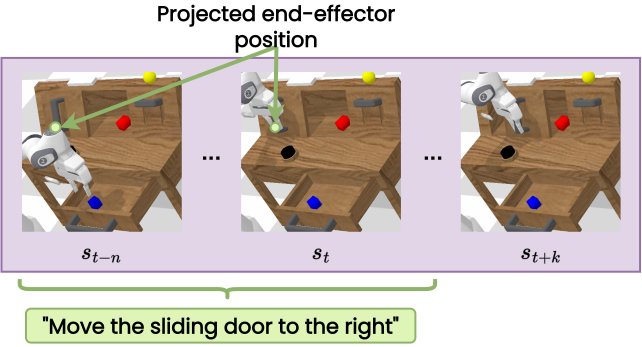
In order to detect affordances in undirected data, we leverage the gripper open/closesignal during teleoperation to project the end-effector into the camera images. Intuitively, this allows the affordance model to learn to predict a pixel corresponding to an object that is needed for completing a task.
We evaluate our approach by giving the agent several instructions in a row. To generate the sequence of instructions we make two experiments. On the first, we use gpt-3 playground to split a general long-horizon instruction into a sequence of multiple smaller-horizon instructions. On the latter one, we manually give sequential instructions to the agent while inspecting its behavior.
Our model is able to understand and perform a wide range of instructions. Furthermore, the use of large language models allows it to generalize to new instructions with a similar semantic meaning.
@inproceedings{mees23hulc2,
title={Grounding Language with Visual Affordances over Unstructured Data},
author={Oier Mees and Jessica Borja-Diaz and Wolfram Burgard},
booktitle = {Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)},
year={2023},
address = {London, UK}
}

